
I’ve been fascinated by how it's 2025, and yet AI still trips over simple facts - even when it sounds brilliantly intelligent. Have you noticed? Ever asked a model a straightforward question and gotten a confidently wrong answer? Let’s unpack this.
In AI, a hallucination is when a model confidently outputs something false, fabricated, or nonsensical. It’s not about perception - like humans hallucinate - it’s more like making stuff up that sounds real. Technically, some experts prefer the term “confabulation” because the model fills gaps with plausible but invented details.
These missteps stem from several root causes:
LLMs don’t understand facts. They predict text based on word patterns from data. If they haven’t seen the real answer, they fill in blanks with guesswork.
If the dataset lacks accurate info - or overrepresents certain narratives - models may create inaccurate outputs, especially on niche topics.
Every token is predicted based on probability. Even coherent text can be false, simply because it's “plausible.”
Models only know data up to a certain date. When asked about newer events, they either guess or hallucinate.
Minor prompt tweaks - or glitch tokens - can lead to entirely wrong answers. Something like “The Nitrome” vs “The Nitrome” can confuse the model.
Even advanced models falter on simple tasks. Google DeepMind’s CEO called it “artificial jagged intelligence” - sharp in some areas, clumsy in others.

Recently, Time found AI systems often disagree - or even echo misinformation. That undermines their reliability.
There’s no miracle cure - but here’s what helps:
But total elimination isn’t possible—because the model architecture itself is probabilistic.
| Why Hallucinations Occur | Mitigation Steps |
| Predictive, not factual | Grounded with real data (RAG) |
| Faulty or incomplete data | Improve dataset quality |
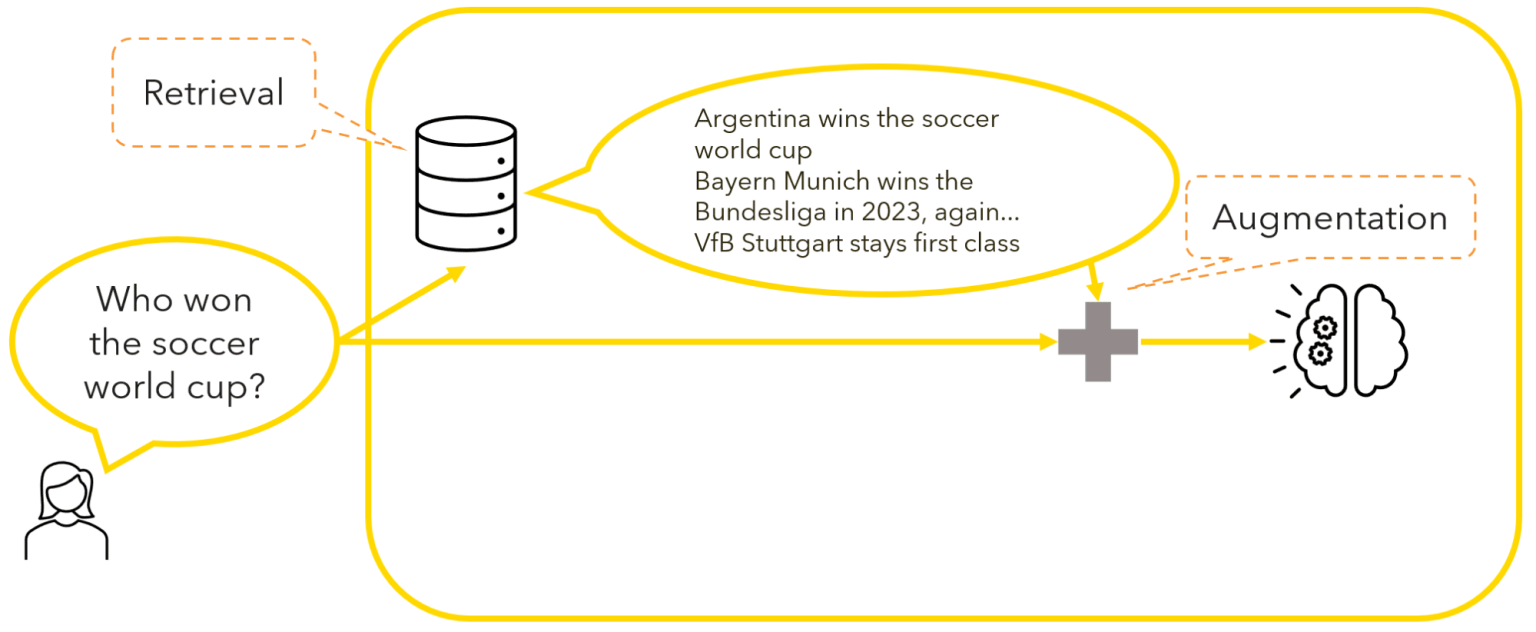
| Knowledge cutoffs | Use retrieval or plugins |
| Inherent probabilism | Add reasoning and validation |
| Glitches & prompt errors | Robust prompting & testing |
| Jagged capability | Benchmark across domains |
AI hallucinations highlight why we must “trust but verify.” They’re not just glitches - they reveal the gap between human reasoning and algorithmic mimicry. But with better data, transparent grounding, and smart safeguards, we can steer toward more accurate, trustworthy AI.
Would you like to explore a specific example or take a deeper dive into one mitigation technique? I’d love to tailor the next section to your interests.
Be the first to post comment!

Instagram Reels have become one of the most powerful organic discovery engines o...
Sakshi Dhingra2 days ago

I don’t judge an AI image generator by “one pretty output.” I judge it by what h...
Sakshi Dhingra3 days ago

AI music generation has matured quickly over the last few years, but the reality...
Sakshi Dhingra4 days ago

AI study tools are everywhere right now. Some feel overhyped. Some feel confusin...
Sakshi Dhingra4 days ago

When I test AI voice generators seriously, I don’t judge them by demo clips. I t...
Sakshi Dhingra5 days ago

When I first discovered Gizmo AI, it immediately positioned itself as something...
Sakshi Dhingra5 days ago