
When I first landed on Qwen.ai, it didn’t look like a flashy startup pitch deck; it looked like a research hub.
The homepage highlighted Qwen 2.5 Max, their flagship model powering both the Qwen Chat interface and the Alibaba Cloud Model Studio API.
Right away, I noticed something unusual: every link pointed to open weights, Apache 2.0 licensing, and a developer-first ecosystem, the exact opposite of the black-box trend most LLMs follow.
From there, I tested the web chat and downloaded the Android app to check latency on mobile.
The responses were surprisingly quick, on par with ChatGPT’s mid-tier models, and available for free.
Naturally, I wanted to understand what’s running under the hood.
At first, I kept mixing up the versions: Qwen 2.5, Qwen 2.5 Max, Qwen 3, and Qwen 3-Max.
Here’s how I now frame it:
What impressed me most was licensing: Qwen is distributed under Apache 2.0, meaning commercial use is allowed. That’s why researchers and startups are already hosting it on-prem without worrying about vendor lock-in.
With that flexibility in mind, I wanted to see how it behaves in the real world, not just in benchmarks.
I started with everyday productivity, summaries, emails, and quick code snippets.
On Qwen Chat, I asked it to analyze a blog draft and fix tone inconsistencies. It rewrote paragraphs smoothly, respecting my phrasing, something smaller open models often botch.
Then I switched to Chinese and Hindi prompts to test the multilingual range. Qwen handled both almost natively, switching back to English when I requested a translation.
Community reports on TechPoint Africa confirm the same: Qwen’s multilingual accuracy is one of its standout advantages.
For developers, Qwen also integrates neatly into RAG pipelines or chatbots because it exposes standard API endpoints and has open weights on Hugging Face.
But before recommending it to my team, I had to evaluate its coding muscle.
I moved to the Qwen Coder model to see if it could replace my daily helper for Python and JS.
Initial tasks—simple calculators, data-cleaning functions, worked perfectly. Qwen even explained its logic clearly.
But when I threw in debugging tasks, things got trickier. As InfoWorld noted, “Qwen Code is good, but not great.” It occasionally misidentified logic errors or suggested partial fixes.
On Reddit’s LocalLLaMA thread, developers echoed that experience: great at writing new code, inconsistent at fixing existing ones.
So I reframed my use, let Qwen Code write from scratch, and keep human oversight for debugging.
Given that balance, the next logical question was cost and access.
Unlike many closed models, Qwen lets me choose between free web use, cloud API, or self-hosting.
Free tier: The Qwen Chat site allows unlimited testing with light rate-limits.
API (Alibaba Cloud Model Studio): Pay-as-you-go; integrates easily with Zapier or LangChain.
Self-hosted: Grab the weights from Hugging Face and deploy locally, perfect for data-sensitive teams.
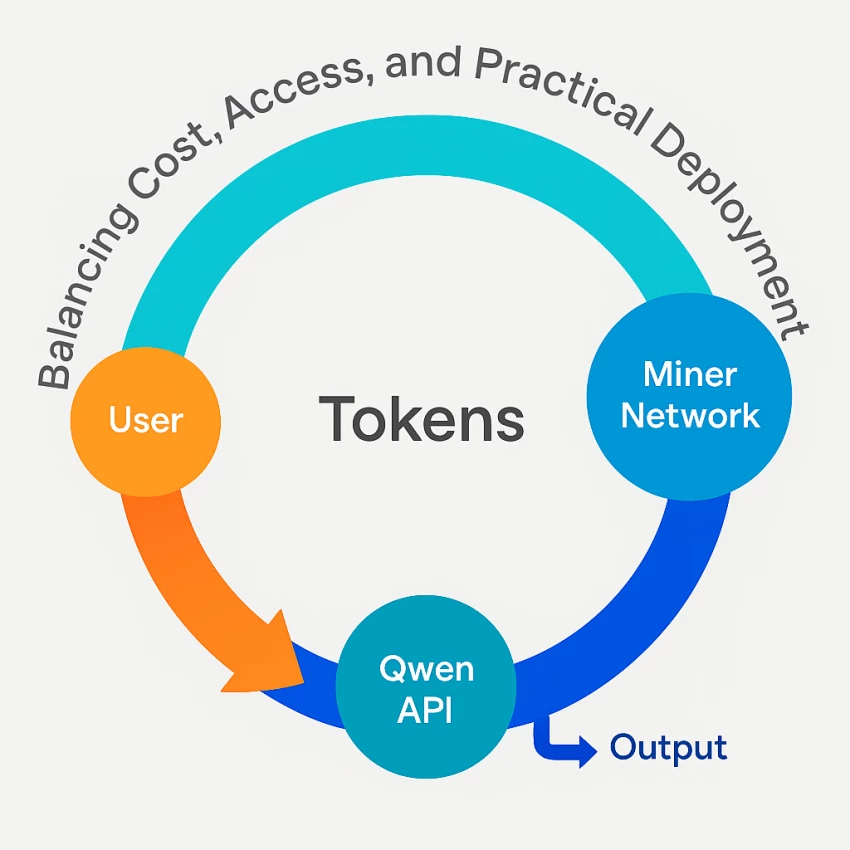
Even InfoWorld highlights Qwen’s “generous free tools with balanced usage limits.”
However, if you access it through third-party brokers like OpenRouter, costs can rise per 1K tokens, as several Redditors warned.
Once cost was clear, I shifted focus to reliability: can it sustain production-level loads?
Benchmarks can be deceiving, so I ran live workflows.
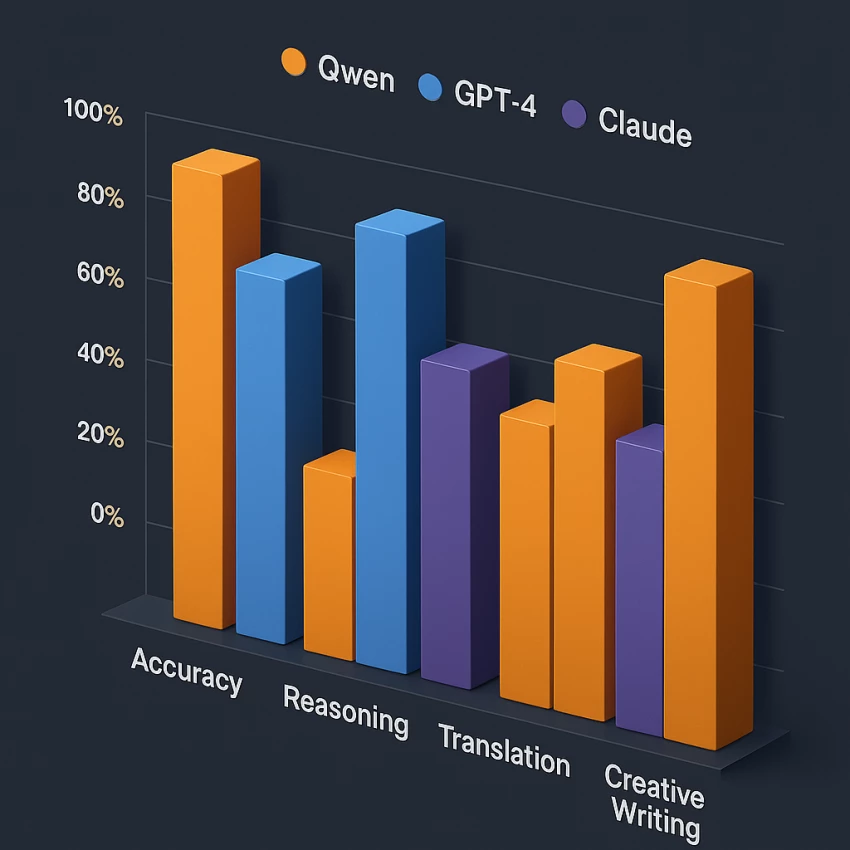
This aligns with Digital Defynd’s and Eesel AI’s reviews: Qwen’s theoretical benchmark scores don’t always match real-world variance, yet it consistently delivers strong reasoning, math, and translation performance.
That makes it ideal for assistant-style deployments or internal productivity bots, but I wouldn’t yet rely on it for mission-critical software debugging.
So, where exactly does Qwen shine for me day-to-day?
Here’s how I’ve positioned it across my toolchain:
Where I don’t use it: full-stack code generation for clients or high-risk automation. There, I still rely on premium closed models
Yet I keep returning to Qwen because its roadmap moves faster than nearly any other open LLM family.
Scrolling through the official blog and the main site’s Qwen3-Max page, I can see the pattern: Alibaba is iterating every 3–4 months.
The Qwen 3-Max release (mid-2025) focuses on higher reasoning accuracy and expanded context length—rumored to exceed 128 K tokens.
At the same time, community reports on Zapier’s LLM roundup praise its “production-ready efficiency with open compliance.”
This evolution signals that Qwen isn’t chasing hype; it’s methodically becoming the open foundation for enterprise AI in Asia and beyond.
That brings me to the most practical part: how to test it quickly before committing.

Here’s the practical checklist I use whenever a new team wants to test Qwen before rollout:
Day 1–2 – Fluency & Context
Day 3–4 – Cloud API Benchmark
Day 5–6 – Self-Hosting Trial
Day 7 – Compare & Decide
This method gives a realistic feel of both cloud convenience and on-prem control.
After several such trials, my conclusion has stayed remarkably consistent.
Qwen has become my default open model family for experimentation, writing, and lightweight deployments.
It’s flexible, affordable, and legally clear, traits most enterprises crave.
Is it perfect? No.
For code debugging, it still trails GPT-4-Turbo; for deep creative writing, it occasionally over-summarizes.
But its balance of openness, cost, and quality is unmatched right now.
I love that I can host it, fine-tune it, or just chat with it, depending on the project.
And knowing Alibaba keeps releasing frequent upgrades, from Qwen 2.5 Max to Qwen 3-Max in just six months, makes me confident this ecosystem will keep accelerating.
If you’re tired of paying API premiums or worrying about data privacy, Qwen is the rare model that lets you build without barriers.
It’s not just an open-source LLM; it’s a glimpse at how enterprise AI might finally become truly open.
Be the first to post comment!

Unlucid AI is one of those tools that looks simple on the surface but becomes mo...
Sakshi Dhingra1 day ago

I’ve tried almost every AI design tool out there.Not casually, I used them for c...
Sakshi Dhingra1 week ago

I didn’t start using AI tools because they were trending.I started because editi...
Sakshi Dhingra1 week ago

At one point, Canva stopped being enough for me. Not because it’s bad, but becau...
Sakshi Dhingra1 week ago

Why People Start Looking Beyond Janitor AIJanitor AI built its popularity on fre...
Sakshi Dhingra1 week ago

The Moment That Made Me Try Both ToolsThere’s a point where creating videos stop...
Sakshi Dhingra1 week ago