
How this AI technique (RAG) is reshaping the way we use large language models
If you’ve ever wished your AI assistant could pull in real, up-to-date, factual information instead of just making educated guesses, you’ve already wished for something RAG is built to do. Retrieval-Augmented Generation (RAG) is one of the most exciting innovations in AI right now, because it combines two powerful techniques: information retrieval and text generation, into one workflow.
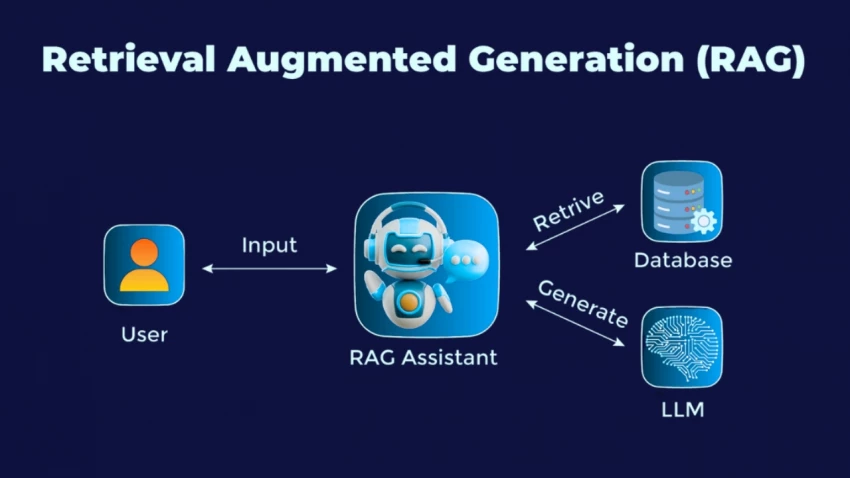
In simple terms, RAG lets AI look things up before it answers you.
Large language models (LLMs), such as GPT, LLaMA, or Claude, are trained on massive datasets. But no matter how big their training data is, they have two big limitations:
This is where RAG comes into play. Instead of relying only on memory, it fetches relevant documents from an external source—such as a database, a search index, or even the internet—and uses them as the foundation for creating a response.
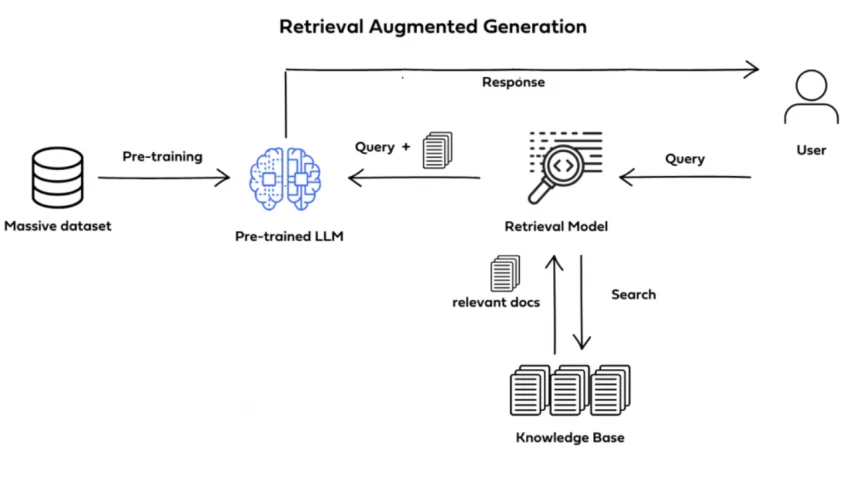
Think of RAG as a two-step process:
This process allows the AI to “see” current, domain-specific, or proprietary information without retraining the model from scratch.
Let’s say you ask a chatbot:
“What are the latest battery technologies for electric vehicles in 2025?”
Without RAG, the AI might guess based on its 2023 training data, possibly missing recent breakthroughs.
With RAG, the system would:
Several open-source and commercial tools make building RAG systems easier:
RAG is most valuable when:
For example, a financial AI tool could retrieve market data from Bloomberg, while a legal assistant could pull from court rulings.
Even though RAG is powerful, it’s not magic. Common challenges include:
RAG is a stepping stone toward real-time, grounded AI. Future improvements may include:
We’re already seeing RAG power advanced applications in healthcare, customer service, market intelligence, and enterprise search.
Retrieval-Augmented Generation is the bridge between a static AI model and a constantly changing world. By letting AI “look things up” before answering, RAG makes responses more current, more accurate, and more trustworthy.
If you’ve ever been frustrated by an AI confidently telling you something outdated or wrong, RAG is the fix.
Be the first to post comment!
Introduction: Why Sales Automation Is No Longer OptionalToday’s B2B sales enviro...
Michael Hicklen4 weeks ago

Image search has quietly become one of the most powerful discovery, research, an...
Michael Hicklen4 weeks ago

Why Workflow Automation Matters in 2026Automation tools help businesses:● S...
Michael Hicklen1 month ago

1) Foundations :What software review platforms are-Software review platforms are...
Michael Hicklen1 month ago

1. What AI Automation in Daily Work Actually Means?1.1 AI automation in daily wo...
Michael Hicklen1 month ago

1. What Is a CRM?Definition-A CRM (Customer Relationship Management) system...
Michael Hicklen1 month ago