Human–AI Coordination Explained: Empirical Evidence, Benchmarks, and Real-World Implications
by Cheshta Upmanyu - 1 month ago - 4 min read

1. What does “Human–AI Coordination” Mean?
1.1 Technical Definition-
In technical terms, human–AI coordination refers to systems in which:
Human and AI agents mutually adapt their actions over time by maintaining shared task representations, exchanging signals, and dynamically adjusting roles to optimize joint outcomes.
This definition aligns with work in:
● Human–AI Teaming (HAIT)
● Cooperative Multi-Agent Systems
● Human Factors & Cognitive Systems Engineering
Key distinguishing properties (supported by coordination theory and AI teaming literature):
| Property | Required for Coordination | Why It Matters |
| Shared task state | Yes | Prevents divergence in understanding |
| Mutual predictability | Yes | Enables anticipation of actions |
| Bidirectional influence | Yes | Both agents shape outcomes |
| Dynamic role allocation | Yes | Adjusts leadership/followership |
| Feedback loops | Yes | Allows continuous correction |
This is not optional—if any of these are missing, systems degrade into supervision, automation, or delegation.
1.2 Operational Definition-
Operationally, coordination exists when:
● Humans change plans because of AI signals
● AI changes behavior based on human corrections
● Neither agent has unilateral control over task execution
Example (documented in HAI-Eval):
● Human proposes partial solution
● AI identifies constraint violation
● Human revises approach
● AI updates execution path
This is joint problem-solving, not assistance.
1.3 How Coordination Differs from Adjacent Paradigms-
| Paradigm | Human Role | AI Role | Shared Planning | Adaptation |
| Automation | Monitor | Execute | Not Present | Not Present |
| Copilot | Decision maker | Suggest | Partially | Partially |
| Autonomous agent | Supervisor | Decide & act | Not Present | Not Present |
| Human–AI coordination | Co-planner | Co-planner | Present | Present |
Evidence: Collaborative benchmarks consistently show human+AI outperforming both alone, which does not occur in pure Copilot settings.
2. Why Existing AI Systems Struggle with Coordination?
Coordination failure is not a model-size problem — it is a representation and interaction problem.
2.1 Handoff Failures-
Most AI systems assume discrete handoffs:
Human → AI → Human
But real coordination requires:
Human ⇄ AI ⇄ Human (continuous)
Failure mode:
AI completes the subtask without understanding downstream human intent, causing rework.
2.2 Intent Alignment Failures-
Empirical studies show AI lacks:
● Explicit models of human goals
● Representations of why humans choose actions
This leads to:
● Correct outputs at the wrong time
● Optimizing metrics humans don’t care about
Evidence: Theory-of-Mind-augmented agents outperform standard agents in coordination tasks (arXiv:2405.02229).
2.3 Shared Context Collapse-
LLMs:
● Store context token-wise
● Do not maintain a persistent shared state across sessions
Humans:
● Maintain evolving mental models
Result: Context drift in long tasks → miscoordination.
2.4 Trust Calibration Breakdown-
Studies show:
● Humans over-trust confident AI
● Under-trust cautious AI
● Misinterpret uncertainty signals
This creates oscillation between:
● Over-reliance
● Excessive overrides
3. Historical Evidence of Human– AI Coordination Failures :
While few organizations publish failures directly, indirect empirical evidence reveals systemic coordination issues.
3.1 Model Agreement ≠ System Coordination-
In financial fraud systems:
● Multiple AI models showed 61% agreement
● Yet downstream human review caught systemic blind spots
Interpretation:
Model-level accuracy does not translate to human-system coordination reliability.
3.2 Communication Breakdown in Human–Machine Teams-
Psychology experiments demonstrate:
● Performance drops when humans misinterpret AI intent
● Trust mismatches reduce team effectiveness
Key finding: Coordination failures occur even when AI accuracy is high.
3.3 Human-in-the-Loop Limitations-
HITL systems:
● Assume humans intervene occasionally
● Do not support continuous adaptation
This results in:
● Late error detection
● Cognitive overload during intervention
4. The Coordination-Focused Model & Benchmark :
4.1 Design Motivation-
Traditional benchmark test:
● Prediction accuracy
● Task completion
They do not test:
● Adaptation to humans
● Communication effectiveness
● Partner variability
4.2 ORCBench: What It Is?
Open and Real-world Coordination Benchmark (ORCBench) evaluates:
● Partner diversity
● Communication
● Adaptation speed
● Robustness to errors
It introduces heterogeneous human behavior models, not idealized users.
4.3 HeteC Training Framework
HeteC trains AI with:
● Multiple simulated human profiles
● Explicit communication channels
● Reward tied to joint success
Coordination Loop Diagram-
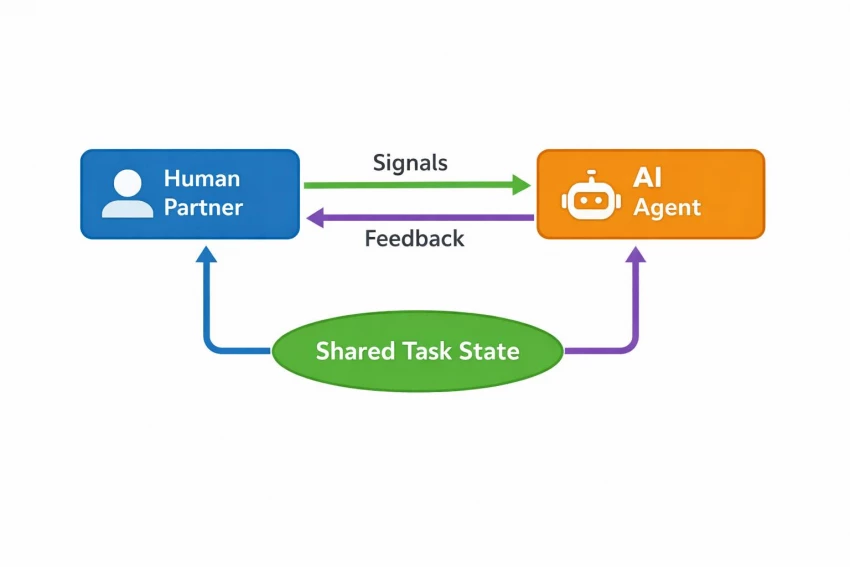
5. How Coordination Is Evaluated :
5.1 Task Types-
| Task | Why It Tests Coordination |
| Collaborative coding | Requires shared reasoning |
| Multi-step planning | Tests long-term alignment |
| Error recovery tasks | Measures correction dynamics |
5.2 Metrics Used-
| Metric | What It Measures |
| Task success rate | Joint outcome quality |
| Latency to alignment | Speed of coordination |
| Human override frequency | Trust & misalignment |
| Correction rate | Communication clarity |
| Performance delta | Net coordination gain |
6. Quantitative Results :
6.1 Performance Comparison (HAI-Eval)
| Setting | Success Rate |
| Human-only | 18.89% |
| AI-only | 0.67% |
| Human + AI | 31.11% |
6.2 Coordination Efficiency Chart-
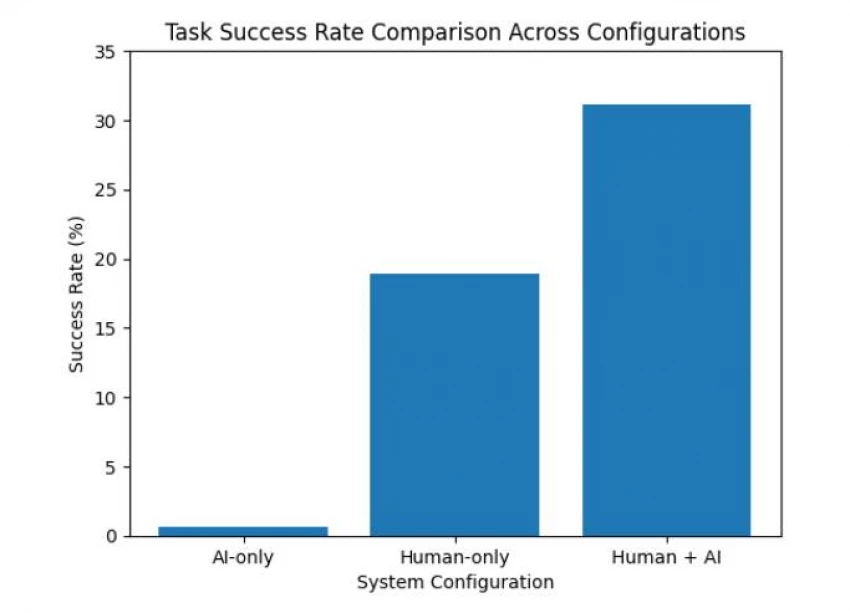
Key insight:
Performance gain exceeds additive effects → evidence of coordination, not assistance.
7. Where Coordination Works and Where It Breaks :
7.1 Works Well In-
| Area | Reason |
| Complex reasoning | Complementary strengths |
| Error recovery | Humans detect, AI adapts |
| Partner variability | Communication aids adaptation |
7.2 Still Breaks In-
| Failure Mode | Cause |
| Long-horizon drift | Weak persistent state |
| Role confusion | No explicit authority model |
| Trust instability | Poor uncertainty signaling |
8. Implications for Real Workplaces :
8.1 Knowledge Work-
● Measurable productivity gains
● Reduced cognitive load
● Better handling of edge cases
8.2 Safety-Critical Domains-
Coordination frameworks:
● Improve resilience
● Reduce brittle automation failures
● Support shared decision authority
9. Final Assessment :
What the data supports-
● Human–AI coordination is distinct
● It is measurable
● It delivers quantitative gains
What remains unproven:
● Generalization across industries
● Long-term stability
● Organizational scalability
Verdict-
Human–AI coordination is a legitimate, emerging frontier, with early empirical validation — but it requires real-world longitudinal evidence before it can be considered the dominant paradigm of applied AI.