AssemblyAI provides speech-to-text and speech understanding models for transcribing and extracting insights from voice data. The platform converts audio streams into text with >93.3% accuracy and offers real-time transcription via WebSocket API with ultra-low latency (~300 ms). Beyond transcription, it includes speaker identification, automatic language detection, and a unified LLM Gateway that integrates transcript-to-intelligence tasks like summarization and entity extraction. The platform handles 600M+ inference calls monthly and processes over 40 terabytes of audio daily, supporting deployment at scale without contracts or throttling.
99% accuracy noisy audio speakers.
Speaker diarization splits conversations.
PII redaction GDPR compliance.
Auto-detects 40+ languages multilingual.
Developer API docs clear fast setup.
Slow real-time processing delays.
Premium features add costs quickly.
Poor audio quality hurts accuracy.
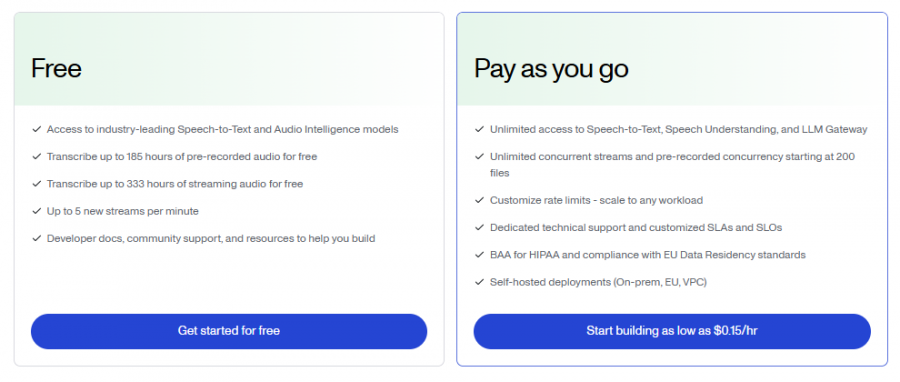
*Price last updated on Feb 16, 2026. Visit assemblyai.com's pricing page for the latest pricing.