
Most people who type Chutes AI into a search bar are not hunting for another polished AI dashboard. They are usually staring at a more specific problem: a model bill that climbed faster than expected,, a side project that needs an OpenAI compatible endpoint without an OpenAI invoice, or a serverless way to run an open-source model without renting and babysitting a GPU.
Chutes AI markets itself straight at that frustration. The pitch is open-source model access, pay-per-token public inference, and serverless GPU compute for private workloads, all without managing infrastructure. On paper, the pricing and model spread look generous enough to pull traffic away from heavier names like OpenRouter, Fireworks AI, and Together AI.
This review checks Chutes AI from five angles that actually decide whether a platform earns a place in a workflow: pricing, model access, setup, reliability, and the friction real users report. Pricing figures come from the official pricing page, capability claims from the official documentation and FAQ, and the complaints from public developer discussion. Where a claim is the company's own and not independently verified, the review says so plainly.
Inference platforms do not reward the same testing that consumer apps do. A chatbot can be judged on its replies. A provider has to be judged on cost behavior, model breadth, integration effort, and how it holds up when traffic spikes. The framework used here, the Inference Layer Review Framework, scores Chutes across six lenses.
| Lens | What it measures |
| Pricing transparency | Whether rates are published, predictable, and free of hidden markups |
| Model variety | Breadth across LLM, image, speech, video, and embedding categories |
| Developer flexibility | SDK and CLI quality, public versus private deployment, and GPU options |
| Beginner friendliness | How quickly a non-specialist reaches a first working request |
| Reliability confidence | Stability under real load, including 429 and capacity behavior |
| Privacy positioning | Stated handling of request data and confidential compute |
Evidence is layered in a fixed order: official pricing and documentation first, then public developer sentiment, then competitor positioning. Capability statements such as uptime and confidential compute are reported as company claims, because they were not independently benchmarked for this review. Community reports are treated as directional signals, not statistics, since forum posts capture loud experiences far more reliably than smooth ones. No third-party star ratings are quoted, because Chutes AI does not yet carry the kind of verified review volume that would make a numeric community score meaningful.
The short version sits in one table before the detail begins.
| Category | Details |
| Best for | Developers and builders who want cheap, per-token access to open-source models, plus serverless GPU compute for private workloads, and who are comfortable rotating models. |
| Not ideal for | Non-technical users who want a plug-and-play chatbot, teams needing guaranteed plugin stability, or anyone unwilling to test reliability before depending on a single path. |
| Pricing model | Public inference is pay-per-token with no subscription, no minimum, and no stated markup. Private Chutes bill by the second at GPU rates from $1.80 per hour, with deployment fees from $5.40. |
| Supported workloads | LLM, image, speech, video, embedding, and content moderation categories, across always-on public models and private custom deployments. |
| Developer experience | Python-focused SDK and CLI, OpenAI-style API usage, and automatic scaling from zero to hundreds of instances on hardware such as H200, MI300X, and B200. |
| Main concern | Recurring community reports of Proxy Error 429, capacity limits, and latency swings that interrupt sustained sessions. |
| Verdict | A capable, cost-attractive inference layer for technical users who test reliability first, not a stable consumer chatbot replacement. |
A common mistake is filing Chutes AI next to consumer chat tools, or treating it as a AI proxy with a fancier name. It is neither. It sits one layer lower, closer to where models are hosted and served than to where they are chatted with.
Two delivery modes define the platform. Public inference exposes always-on, shared open-source models that anyone can call per token, which is the path most end up on. Private Chutes let a team deploy a specific model or custom workload onto dedicated GPU time, billed by the second, which is the path that looks more like managed serverless infrastructure.
That split explains the platform's double personality. The same service that offers fractions of a cent per roleplay reply also offers H200 and MI300X class hardware for production deployments. The open-source catalog leans on open weights rather than a single proprietary family, which is the draw for anyone who wants alternatives to closed APIs. The serverless angle, scaling from zero to many instances without provisioning servers, is the core infrastructure promise.
Confidential compute and tooling. The documentation references trusted execution environments for confidential workloads and a Python-first development kit. The GitHub package is described as the platform CLI and toolkit, and the FAQ recommends Python 3.10 or 3.11, with 3.8 and above supported. Chutes also presents itself with a distributed compute framing rather than a single centralized region, which is part of its identity and also part of why capacity behavior can feel uneven from one hour to the next.
Getting to a first working request follows a predictable path. The friction is rarely the code itself; it is telling the difference between a configuration mistake and a capacity problem.
| Step | What it involves | Common friction |
| Account creation | Signing up and reaching the dashboard | Confirming which balance or billing model applies before spending anything |
| API key or token | Generating a token for authenticated calls | Storing it safely; the key location is sometimes confused with billing settings |
| Base URL and API shape | Pointing the client at the Chutes endpoint using an OpenAI-style request | Getting the exact base URL and path right; a mismatch often looks like an auth failure |
| Model selection | Choosing a model ID from the public catalog | Model IDs must match exactly; a typo reads as an unavailable model |
| Test request | Sending a small prompt to confirm the round trip | Separating a config error from a capacity error on the very first failure |
| Usage monitoring | Tracking token consumption and request volume | Knowing where usage and spend are reported in the dashboard |
| Cost tracking | Mapping per-token rates to expected volume | Per-model pricing means one estimate does not cover every model |
| Fallback planning | Deciding a second model or provider before launch | Skipping this step turns a single 429 into a full outage |
Setup friction worth naming up front The most confusing moment for new users is telling the difference between their own mistake and the platform running out of capacity. An endpoint typo, a wrong model ID, and a 429 capacity error can all surface as the same failed request. A clean diagnostic is to call a small, cheap model with a known-good model ID and a minimal prompt. If that succeeds while a larger model fails, the problem is likely model-specific congestion, not the configuration. |
Asking what Chutes AI costs as if it were a single number is the first habit to break. Pricing is per model, and the spread is wide.
| Model | Input $/1M | Output $/1M | Best use case | Cost caution |
| Mistral-Nemo-Instruct-2407 | $0.0245 | $0.0978 | High-volume roleplay, cheap experimentation | Quality ceiling on hard reasoning tasks |
| Qwen3-32B | $0.104 | $0.416 | Balanced coding and general chat | Output cost rises with long generations |
| Gemma-4-31B-turbo | $0.15 | $0.42 | Fast general-purpose responses | Verify turbo quality trade-offs per task |
| MiniMax M2.5 | $0.15 | $1.20 | Short prompts, longer replies | Output is roughly 8x input; long answers add up |
| DeepSeek-V3.2 | $0.28 | $0.42 | Reasoning and coding at balanced quality | Mid-tier input cost compounds at scale |
| Qwen 3.5 397B | $0.45 | $3.00 | Heavy reasoning, complex tasks | Output at $3 per 1M punishes verbose prompts |
| GLM-5.1 | $1.20 | $4.00 | Top-end quality runs | Most expensive pairing here; reserve for high-value calls |
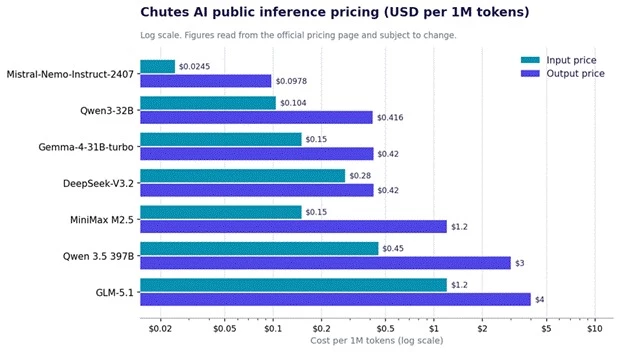
Public per-token pricing across seven Chutes AI models. Output rates drive most of the cost difference.
The math stays simple and worth keeping visible: input tokens divided by one million, multiplied by the input rate, plus output tokens divided by one million, multiplied by the output rate. The scenarios below use rounded token assumptions across three models each, so the same method copies to any model in the catalog.
| Scenario | Token assumptions | Model options and estimated cost |
| 30-minute roleplay chat | About 60,000 input and 9,000 output tokens, context growing each turn | Mistral-Nemo-Instruct-2407: about $0.002 DeepSeek-V3.2: about $0.021 Qwen 3.5 397B: about $0.054 |
| 4-hour coding session | About 640,000 input and 48,000 output tokens | Qwen3-32B: about $0.087 DeepSeek-V3.2: about $0.199 GLM-5.1: about $0.96 |
| Production chatbot test, 1,000 requests | About 700,000 input and 250,000 output tokens | Mistral-Nemo-Instruct-2407: about $0.042 Gemma-4-31B-turbo: about $0.21 MiniMax M2.5: about $0.41 |
These are estimates, not quotes. The real bill moves with model choice, context length, output length, retries, and failed requests. The last factor is easy to forget: a burst of 429 retries during peak hours quietly inflates token spend for responses that never completed cleanly the first time.
No single model wins every workload. The table below maps common goals to the kind of Chutes model that suits them, with the trade-off attached to each.
| Use case | Better Chutes model type | Reason | Risk |
| Roleplay and chat | Small to mid instruct model (Mistral-Nemo-Instruct, DeepSeek-V3.2) | Low per-token cost suits long, chatty sessions | Shared capacity means 429 risk at peak |
| Coding | Reasoning-capable model (Qwen3-32B, DeepSeek-V3.2) | Better structure and logic without top-tier cost | Large code context raises cost and latency |
| Long-context reasoning | Large model (Qwen 3.5 397B, GLM-5.1) | Capacity for complex, multi-step prompts | High output rates; verbose answers get expensive fast |
| Cheap experimentation | Smallest model (Mistral-Nemo-Instruct) | Lowest token cost for rapid iteration | Weaker on hard reasoning and edge cases |
| Image generation | Image category model | Open model access without a separate image vendor | Specific availability and pricing are not in the public LLM rate list |
| Speech and video | Speech or video category model | Covers text-to-speech and video tasks under one account | Maturity and queue behavior vary; least public detail |
| Embedding and search | Embedding category model | Vector generation for retrieval and search | Throughput depends on shared capacity |
| Private custom workload | Private Chute on dedicated GPU (H200, MI300X, B200) | Isolation, control, and confidential-compute options | GPU-time billing, deployment fee, and operational overhead |
Selection comes down to four moving parts: latency tolerance, context length, price per token, and whether the model is actually available when the request lands. The reliable habit is choosing by workload, not by leaderboard.
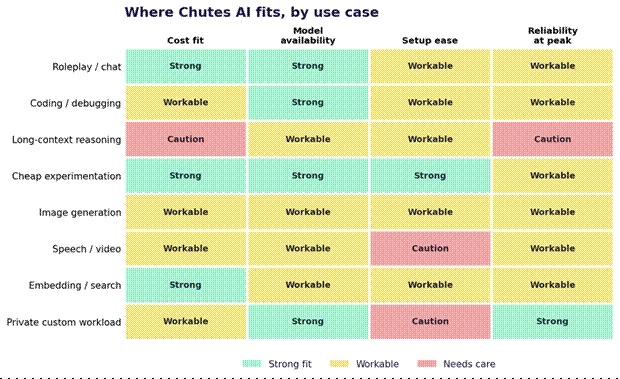
A use-case fit view across cost, model availability, setup ease, and reliability at peak.
Performance is where the marketing and the message boards diverge most. The appeal rests on cheap, flexible model access, but the experience of that access depends heavily on how congested a given model is and whether instances are free when a call arrives. Two users can describe the same platform as a bargain or a coin flip, and both can be telling the truth on different days.
The recurring complaints in public developer discussion cluster tightly: Proxy Error 429 (the signature symptom, usually meaning too many requests or no free capacity), reports of infrastructure at maximum capacity, no instances available for a requested model, latency that swings rather than holding steady, congestion concentrated on a few popular models.
These reports come mostly from Reddit and similar forums, which makes them anecdotal rather than statistical. They still matter. When the same failure appears across many independent posts over time, it stops being noise and starts being a pattern worth planning around. What the posts cannot establish is frequency, since forums collect the bad sessions far more reliably than the smooth ones.
| Problem | Likely cause | User-side fix | Provider-side limitation | When to switch provider |
| Proxy Error 429 | Rate limit hit or no free capacity | Reduce request rate, retry with backoff, trim context | Shared capacity ceiling on popular models | Repeated 429s during the hours work actually happens |
| Infrastructure at max capacity | Demand exceeds available instances | Move to a less congested model | Total instance pool is finite | Capacity fails on every viable model, not just one |
| No instances available | Requested model has zero free instances | Pick an alternate model ID | Model-specific provisioning | A required model is chronically unavailable |
| Latency swings | Variable load and scheduling | Measure first-token latency, avoid peak windows | Distributed scheduling under load | Latency breaks an interactive or SLA-bound use |
| Model-specific congestion | One popular model is overloaded | Route to a comparable model | Popularity concentrates load | The only model that fits keeps stalling |
| Roleplay interruptions | Mid-session capacity or rate issue | Shorten context, lower output length, retry | Shared inference under peak demand | Smooth long sessions are a hard requirement |
None of this makes Chutes AI unusable. It makes it a platform that rewards a fallback plan. The single most effective habit is deciding the second model and the second provider before the first 429 arrives, not during it.
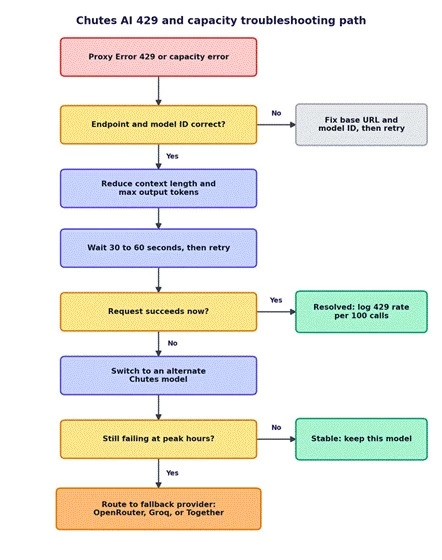
A practical decision path for handling Proxy Error 429 and capacity errors on Chutes AI.
The production side of Chutes AI is more serious than the roleplay framing suggests, and it is where the infrastructure claims actually get tested. Private Chutes turn the service into a serverless deployment target: a custom Python workload or a specific model runs on dedicated GPU time, scaling from zero to many instances as demand moves.
Billing changes shape here. Instead of per-token public rates, private deployments pay for GPU time by the second at hourly rates from $1.80, with deployment fees from $5.40. For bursty or intermittent workloads, second-level billing can be efficient. For steady, predictable load, the math deserves a direct comparison against reserved capacity elsewhere.
Confidential compute is part of the pitch for teams with sensitive data. The documentation references trusted execution environments and encryption, positioned for workloads that cannot run on ordinary shared infrastructure. Those features are valuable if they hold up under scrutiny, which is why they belong in a security review rather than a feature checklist.
The Python-first SDK and CLI fit teams already living in that ecosystem and add friction for teams that are not. Python 3.10 or 3.11 is recommended, with 3.8 and above supported. Production readiness then comes down to the unglamorous work: monitoring request success and latency, planning failover across models and providers, and treating reliability as something measured rather than assumed.
Vendor risk is the closing consideration. The same community 429 reports that annoy a hobbyist become a business problem when a revenue path depends on a single model on a single provider. The reasonable verdict is conditional: Chutes can suit teams comfortable with infrastructure trade-offs and disciplined about fallback, but production users should validate reliability under their own load before making it a dependency.
Privacy is one area where Chutes AI makes strong statements, and strong statements are the ones that most deserve verification. The privacy page indicates that the platform does not log, store, or persist API request or response content, and references trusted execution environments and end-to-end encryption. Those are meaningful commitments for anyone routing user data through a third-party model.
The caution that follows is not skepticism for its own sake. Privacy policies change, scopes differ between public inference and private deployments, and a public claim is not the same as a contractual guarantee or an independent audit. Sensitive personal, legal, medical, or financial data should not flow through any inference provider on the strength of a marketing page alone. Reviewing the current privacy policy, terms, and any enterprise agreement before that point is the minimum due diligence.
| Privacy factor | Official claim | Reviewer caution |
| Request and response content | Stated not to be logged, stored, or persisted | Re-check the live policy; confirm whether private deployments and metadata are covered identically |
| Confidential compute | Trusted execution environment referenced | The scope of coverage and which workloads qualify are not independently verified here |
| Encryption | End-to-end encryption referenced | Confirm what is encrypted in transit versus at rest, and under which plan |
| Uptime and availability | 99.9% uptime SLA stated in documentation | A company claim, not independently benchmarked; community reports suggest real-world variability |
| Sensitive data handling | No special carve-out beyond the above | Avoid personal, legal, medical, or financial data without reviewing current terms and enterprise options |
No inference provider is best at everything, and the honest way to place Chutes AI is against the alternatives people actually weigh it against. RunPod and Replicate sit slightly outside this group because they lean further toward broad custom deployment control, and they are worth a look for teams that want to manage more of the stack themselves.
| Platform | Best for | Pricing style | Model access | Developer control | Reliability | Main drawback |
| Chutes AI | Open-source inference and serverless GPU | Per-token public, GPU-second private | Broad open models plus private deploy | High (SDK, CLI, GPU choice) | Cheap but variable; test under load | Capacity and 429 reports |
| OpenRouter | Many models behind one API | Per-token, unified billing | Very broad marketplace | Moderate (routing layer) | Generally stable | Less low-level control |
| Groq | Speed-focused inference | Per-token | Narrower curated set | Moderate | Fast, generally reliable | Smaller model selection |
| Fireworks AI | Production inference workflows | Per-token plus dedicated | Strong open plus some proprietary | Good (fine-tuning, dedicated) | Established, production-grade | Cost at scale |
| Together AI | Production open-model inference | Per-token plus dedicated | Very broad open models | Good (fine-tuning, dedicated) | Established, production-grade | Cost at scale |
Traditional review-site coverage for Chutes AI is thin compared with mainstream software, and inventing a Trustpilot or G2 score to fill that gap would be the opposite of helpful. The platform has not accumulated the kind of verified, high-volume review trail that supports a clean numeric community rating. What exists is three layers of signal, each useful and each limited.
| Source type | Positive signals | Negative signals | Trust level |
| Official docs and pricing | Transparent per-token rates, broad model access, production features | Self-reported and not third-party verified | Medium |
| Developer and community discussion | Real low-cost access, open-model availability, active roleplay and developer usage | Recurring 429, capacity, and latency complaints; instability at peak | Medium |
| Third-party guide pages | Setup walkthroughs, alternative roundups, growing coverage | Thinner than mainstream tools; some pages are SEO-driven | Low to medium |
One specific trap deserves a flag. Some search results for the word Chute on a major review site appear to point at a different product or listing, not Chutes AI. Those should not be cited as Chutes AI reviews unless the listing is manually verified to match the platform. Borrowing another product's ratings would mislead readers in exactly the way this review is built to avoid.
Anyone evaluating Chutes AI seriously can run a short, repeatable test before committing. The checklist below is built to be measured, not just read.
| Test | Purpose | What to record |
| Test three models, not one | Avoids judging the platform on one model's day | Quality and latency per model |
| Measure first-token latency | Captures perceived responsiveness | Milliseconds to first token |
| Measure full response time | Captures throughput | Total seconds per request |
| Check 429 frequency at peak | Reveals reliability under real load | 429 count per 100 requests, by hour |
| Compare cost per 100K tokens | Turns rates into a real budget line | Dollar cost per 100K across models |
| Test long-context stability | Stresses context handling under load | Success rate at high token counts |
| Test fallback routing | Confirms resilience | Time to recover via alternate model or provider |
| Check privacy and logging needs | Matches policy to data sensitivity | Whether the data type is allowed under current terms |
| Monitor failed and retried requests | Surfaces hidden cost and instability | Retry rate and wasted spend |
| Pros | Cons |
Direct access to a broad set of open-source models Pay-per-token public inference with no subscription or minimum Private Chute deployments for custom workloads Trusted execution environment and confidential-compute positioning Python SDK and CLI for programmatic control Potentially very low costs on smaller models Flexible across many deployment and use-case patterns | Pricing varies widely by model and needs per-model checking Confusing for non-technical or first-time users Recurring community reports of 429 and capacity issues Python-focused deployment narrows the audience Production reliability has to be tested, not assumed Limited traditional third-party review data Not a drop-in consumer chatbot replacement |
Chutes AI earns a clear but conditional recommendation. It is worth testing for anyone who wants flexible access to open-source models, lower-cost inference, or serverless GPU deployment without owning and operating infrastructure. The per-token economics on smaller models are genuinely attractive, the private-deployment path is capable, and the privacy posture is stated more seriously than most.
It is the wrong choice for anyone who needs a perfectly stable, plug-and-play chatbot provider,, or hand-holding support for a first API integration. The recurring 429 and capacity reports are not fatal, but they are real, and they punish workflows with no fallback.
The smart way to approach the platform is to treat it as a powerful but technical inference layer rather than a finished product. Test pricing on the specific models that matter, measure latency and 429 behavior during the hours that matter, line up a fallback model and provider, and review the privacy terms against the data involved. Used that way, Chutes can be a sharp tool. Adopted blindly, it can be a source of avoidable outages.
| Dimension | Justification | Score |
| Pricing transparency | Rates published for public and private use; held back only by per-model variation and missing context-window detail | 8 / 10 |
| Model variety | Broad coverage across LLM, image, speech, video, and embedding; not as vast as a pure aggregator | 8 / 10 |
| Developer flexibility | SDK, CLI, public and private paths, and high-end GPU options reward technical teams | 8 / 10 |
| Beginner friendliness | Python focus plus endpoint, model-ID, and capacity friction make a rough first experience | 4 / 10 |
| Reliability confidence | Community 429 and capacity reports plus an unverified SLA keep confidence guarded until tested | 5 / 10 |
| Privacy positioning | Strong stated handling and confidential-compute claims, limited by being self-reported and changeable | 7 / 10 |
| Overall verdict | A cost-attractive, capable inference layer for technical users who plan for reliability, not a turnkey chatbot | 7 / 10 |
Share your thoughts about this article.
Be the first to post a comment!

Artificial intelligence is beginning to influence entire transportation networks...
Deepak Mehra1 day ago

Quick answerBlackbox AI is an AI coding assistant used for generating code, debu...
Harpreet Singh2 days ago

I did not set out to write a warning. I set out to find a cheap, fast tool that...
Nitin3 days ago

Job hunting in 2026 feels like a part-time job you never applied for. You refres...
Deepak Mehra5 days ago

You-TLDR is useful when you do not want to sit through a full YouTube video just...
Harpreet Singh5 days ago

Type "openfuture ai" into Google and you will find a strange mix of results. Hal...
Sakshi Dhingra5 days ago