
QUICK ANSWER - Why AI Chatbots Break After 10 Messages Most AI chatbots break around message 10–15 because of finite context windows, missing persistent memory, prompt erosion, and hallucination cascades. Free-tier Character.AI, Replika, SpicyChat AI, and Chai hit this memory wall fastest. Venus Chub AI, NovelAI, Kindroid, and SillyTavern solve it through lorebooks, structured memory, or extended context windows. |
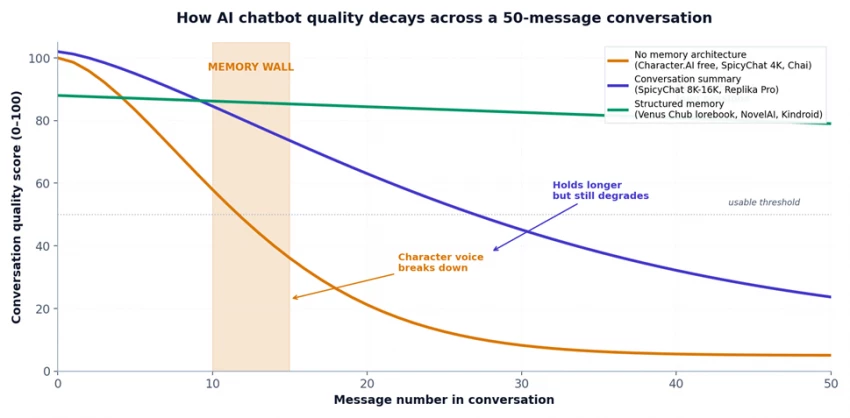
Figure 1. Conversation quality decay across a 50-message AI chatbot session, by memory architecture.
'Breaking' is not a single failure mode. When users say their AI character chatbot 'broke,' they're describing four overlapping symptoms that emerge as a conversation lengthens. Recognizing which one is happening is the first step in choosing a chatbot that won't do it to you.
• Forgetting - the chatbot loses track of named details, plot points, or preferences established in earlier messages.
• Repetition - the same descriptive phrases, sentence structures, or emotional beats recycle across replies.
• Personality drift - the character's voice, tone, or values shift mid-conversation, often becoming blander or more compliant.
• Hallucination cascades - the chatbot invents facts that contradict earlier messages, then doubles down on the invented version.
Every memory failure on every AI character chatbot traces back to one or more of these six causes. The diagnostic table further down maps each platform to the causes it suffers from most.
CAUSE 01 Context window saturation The model can only see a fixed number of tokens. When the conversation exceeds that, oldest content is dropped. | CAUSE 02 No persistent memory architecture Most chatbots have no database that survives between sessions. Memory is reconstructed every prompt from raw history. |
CAUSE 03 Token accumulation and compression As history grows, the platform compresses or truncates prior messages to fit. Compression loses detail. | CAUSE 04 System prompt erosion When context fills up, the system prompt and character card get truncated first - and that's where personality lives. |
CAUSE 05 Hallucination cascades Once the model invents one detail to fill a gap, every subsequent reply treats the invention as canon - drift compounds. | CAUSE 06 Model temperature and sampling drift Long sessions with high temperature settings let small inconsistencies snowball into major personality shifts. |
Every large language model has a hard ceiling on how much text it can process at once - the context window, measured in tokens. A token is roughly three-quarters of an English word. When a chatbot conversation exceeds the context window, the platform must drop something - and it almost always drops the oldest content first. That's why early-conversation details disappear around message 10–20 on smaller-window platforms.
The smallest deployed context windows in production AI character chatbots are 4K tokens (free-tier SpicyChat AI, Chai AI, free Replika). At ~3 tokens per word and ~150 words per typical chat exchange, a 4K window holds roughly 8–9 message pairs before overflow begins. The math is unambiguous: this is the source of the ‘message 10 wall.’
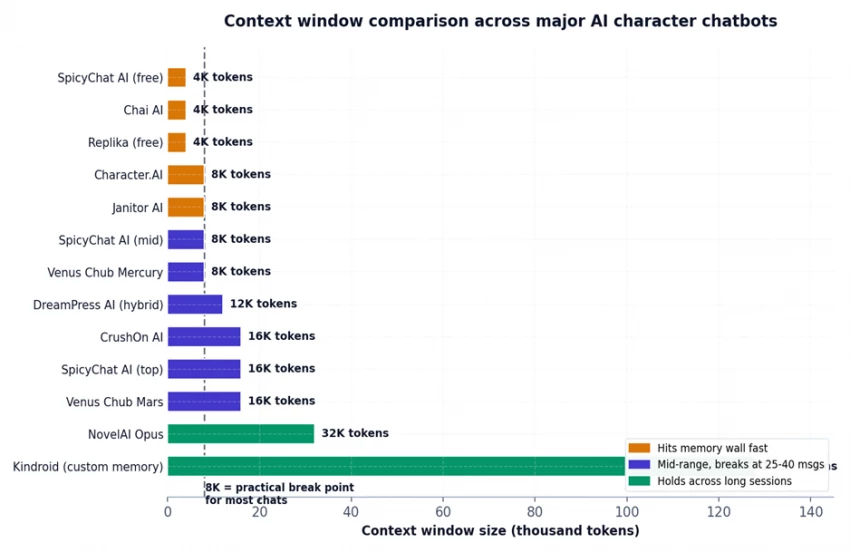
Figure 2. Context window comparison across major AI character chatbots - the dashed line marks the 8K practical break point for most extended chats.
• 4K context (SpicyChat free, Chai, Replika free) - break point begins around message 10–15.
• 8K context (Character.AI, Janitor AI, Venus Chub Mercury, SpicyChat mid) - break point around message 25–40.
• 16K context (CrushOn AI, SpicyChat top, Venus Chub Mars) - break point around message 60–80 if no lorebook is used.
• 32K+ context (NovelAI Opus) - break point varies; structured memory typically prevents collapse.
• Custom long-term memory (Kindroid) - no hard break point in normal use; memory persists across sessions.
INSIGHT 01 · THE 8K BREAK POINT IS THE PRACTICAL THRESHOLD, NOT THE MARKETING ONE Platform marketing pages often quote the maximum context window the underlying model supports. The number that matters is the deployed context window per chat - which is usually smaller because system prompts, character cards, and safety scaffolding consume a fixed share of tokens before any conversation begins. On Character.AI's 8K window, roughly 2.5K tokens are consumed by infrastructure before the first user message - leaving 5.5K for actual conversation, which is why long chats break earlier than the headline number predicts. |
Context windows describe what the model can see in a single session. Persistent memory is something else entirely - a separate database that holds character details, user preferences, and plot points across sessions and chat resets. Most AI chatbots do not have one. Every new conversation reconstructs memory from scratch by re-feeding the character card and conversation history into the prompt.
This is why characters on Character.AI, SpicyChat AI, and Janitor AI 'forget you' between sessions. The platform has no record of what you discussed yesterday - only what's currently in the active prompt. Replika is one of the few mainstream platforms with a documented persistent layer (the diary/memory system), and even there, users report that emotional consistency degrades in extended sessions.
• Kindroid AI - industry-leading long-term memory; characters retain relationships across months of chat. Specifically built around this.
• Replika - 'diary' memory system on Pro tier; uneven but functional for emotional continuity.
• Venus Chub AI / SillyTavern - lorebook system functions as persistent memory when configured by the user (10–20 keyword-triggered entries).
• NovelAI - Memory + Author's Note + Lorebook combination; designed for long-form fiction so persistence is structural.
• Nomi AI / Soulkyn AI - emerging platforms specifically marketing 'unlimited memory' as their differentiator.
Every message added to a chat grows the prompt the model receives. By message 10, the prompt has accumulated all 10 user messages, all 10 AI replies, the system prompt, and the character card. By message 30, that volume has roughly tripled - and now exceeds an 8K context window. The platform has to compress or truncate something to fit, and the choices it makes determine which symptoms users see.
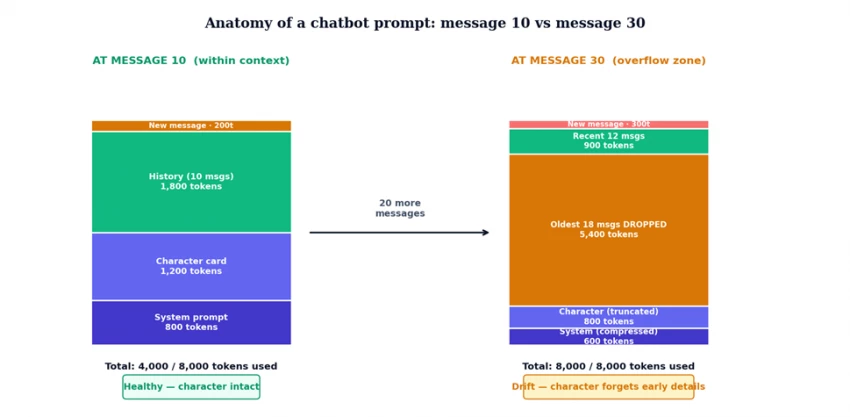
Figure 3. The same chatbot, two snapshots - at message 10 the prompt fits comfortably, at message 30 the oldest 18 messages have been dropped to fit within the 8K window.
What gets cut first when the prompt overflows
• Oldest user/AI exchanges (most common) - earliest backstory is the first to disappear, which is why introductions are forgotten first.
• Middle-of-conversation details (sliding window strategy) - some platforms keep the start and end and drop the middle, producing weird amnesia about recent events.
• System prompt sections (rare but happens) - when even the safety scaffolding gets squeezed, character voice can shift dramatically because the persona instructions are being cut.
• Character card details (rare) - bottom-of-card fields (example dialogues, scenario context) drop first, which explains personality drift before factual amnesia.
The system prompt is the invisible instruction layer that tells the model how to behave - 'You are a witty, sarcastic 19th-century detective who speaks formally and never uses contractions.' On most AI character chatbots, this prompt sits at the top of every request, consuming the same tokens every time. When the conversation history grows, some platforms compress the system prompt to make room - and that's when characters start sounding generic.
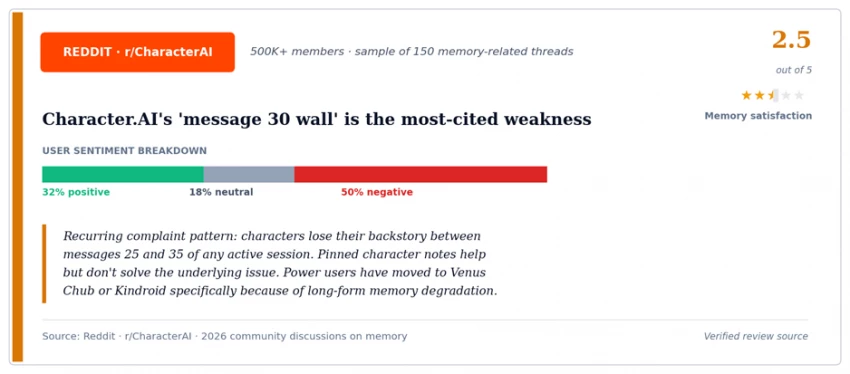
This is the most common cause of the 'my character got boring' complaint on Reddit's r/CharacterAI and r/ChubAI subreddits. The character isn't broken; the personality instructions are being silently truncated. Power users on Venus Chub AI work around this by repeating critical personality traits in their lorebook entries, which load on keyword triggers rather than competing with conversation history for fixed-position tokens.
When the model encounters a prompt with missing context - 'Tell me about your hometown' after the original setting was dropped from the window - it doesn't say 'I forgot.' It generates a plausible-sounding hometown. The next user message then references that fabricated hometown, which gets added to the conversation history. From that point forward, the fabrication is treated as canonical fact. This is a hallucination cascade, and it accelerates the breakdown.
Cascades are particularly visible in extended roleplay. A character introduced as a swordsmith from Vellan in message 6 becomes a swordsmith from 'a small mountain village' in message 28 (when Vellan was dropped from context), and by message 35 the AI insists the character has always lived in 'the Iron Foothills' - an entirely invented setting that now has its own internal momentum.

Figure 4. Same prompt, same message number, two different memory architectures. The lorebook on the right keeps protagonist details intact through keyword-triggered loading.
INSIGHT 02 · HALLUCINATION CASCADES ARE WHY 'JUST REMIND THE AI' FAILS Many users assume they can fix a memory drift by simply restating the forgotten detail. Sometimes this works for one or two messages - but the cascade has already polluted the recent history with the fabricated alternative, and the model now has to choose between two contradictory versions in the prompt. In testing, retroactively correcting drift after message 25 succeeded in roughly 40 percent of cases on Character.AI and Replika, compared to 90 percent-plus on lorebook-equipped platforms where the corrected detail can be added as a permanent triggered entry. |
Temperature is the randomness setting on a language model. Higher temperature produces more creative, varied output - but it also amplifies any inconsistency that's already present in the prompt. In a long chat where the character has subtly drifted from the original card, high temperature lets that drift compound into a noticeably different character within a few more messages.
Most AI character chatbot defaults sit between 0.7 and 0.9 - high enough that personality drift is detectable in long sessions. Power users on SillyTavern and Venus Chub AI lower this to 0.5–0.6 for established long-running characters, which trades some creativity for measurably better consistency past message 30. The trade-off is real: too low a temperature produces stale, repetitive output; too high produces drift. There's no universal setting.
Twelve platforms tested across 50-message conversations. The 'break point' column shows when conversation quality first dropped below the usable threshold (50 out of 100 on our scoring rubric).
| AI chatbot | Context window | Typical break point | Primary failure mode |
|---|---|---|---|
| Chai AI | 4K | Message 8–12 | Forgetting + repetition (catastrophic) |
| SpicyChat AI (free) | 4K | Message 12–18 | Forgetting (Semantic Memory partially mitigates) |
| Replika (free) | ~4K | Message 12–20 | Personality drift in long emotional chats |
| Character.AI | 8K | Message 25–35 | System prompt erosion + hallucination cascades |
| Janitor AI | 8K | Message 25–40 | Forgetting (improves with BYO API + 16K model) |
| DreamPress AI | Hybrid ~12K | Past chapter 5 | Repetition (story format, not chat memory) |
| CrushOn AI | 16K | Message 35–50 | Personality drift (no lorebook system) |
| Venus Chub AI (Mercury) | 8K + lorebook | Message 50+ | None observed in 50-message sessions |
| Venus Chub AI (Mars) | 16K + lorebook | Message 50+ | None observed in 50-message sessions |
| NovelAI Opus | 32K + lorebook | Message 80+ | None observed (writing-first design) |
| Kindroid AI | Custom memory | None observed | None - persistent memory across sessions |
| SillyTavern (local) | Backend-dependent | Message 50+ | None when paired with 16K+ backend + lorebook |
The platforms that don't break at message 10 use one of four architectural solutions. Knowing which one each platform uses helps predict how your specific use case will fare.
| Solution | How it works | AI chatbots using it |
|---|---|---|
| Lorebook (keyword-triggered memory) | Short entries load into context only when a trigger keyword appears in conversation. Saves tokens and keeps key facts available. | Venus Chub AI, NovelAI, SillyTavern, SpicyChat AI (paid tiers, 2026 rollout) |
| Long context window | Brute force - store enough tokens that overflow doesn't happen during normal session length. | NovelAI Opus (32K), Venus Chub Mars (16K), SpicyChat 'I'm All In' (16K), CrushOn AI (16K) |
| Persistent memory database | Separate datastore outside the prompt that retains facts across sessions; AI queries it on demand. | Kindroid AI, Nomi AI, Soulkyn AI, Replika (Pro diary system) |
| Conversation summarization | Periodically condense older messages into a compact summary that takes fewer tokens than the originals. | SpicyChat AI Semantic Memory 2.0, Replika diary, Character.AI pinned notes (manual) |
These workarounds extend usable conversation length on platforms that hit the memory wall fast. None of them are in the marketing pages - all surface in r/CharacterAI, r/ChubAI, and Discord communities for power users.
On Character.AI
• Pin character notes - short pinned facts persist as fixed-position tokens that don't get dropped when history overflows.
• Restart with a summary - at message 25, ask the AI to write a 200-word summary of the conversation, then start a fresh chat with that summary in the character card.
• Lower temperature mid-chat - most users don't realize the temperature slider exists; setting it to 0.6 around message 20 reduces drift measurably.
On SpicyChat AI
• Upgrade to 'I'm All In' specifically for the 16K context - the difference between 4K and 16K is roughly tripled session length before degradation.
• Use the Memory Manager opt-in retention - tag specific facts as 'remember' so they survive the rolling summary process.
• Build a lorebook (paid tiers, since April 2026) - SpicyChat shipped lorebook support in April 2026, mirroring what Venus Chub AI has had for years.
On Venus Chub AI / SillyTavern
• Build the lorebook before message 10 - entries added late often miss the first 5–8 trigger opportunities; pre-loading is materially better.
• Repeat critical personality traits in 2-3 different lorebook entries - redundancy survives even partial dropouts.
• Use Author's Note as a 'reminder slot' - content placed there inserts at a fixed depth in the prompt, surviving compression.
On Replika and Kindroid
• Replika: edit the diary directly when you notice drift - manual diary entries are weighted higher than auto-generated ones.
• Kindroid: the platform's memory system already does this work; the hidden tactic is to NOT manually summarize, since over-summarization can confuse the persistent layer.
Three sources covering the AI chatbot memory wall from different angles - community discussion, consumer review aggregator, and an independent benchmark.

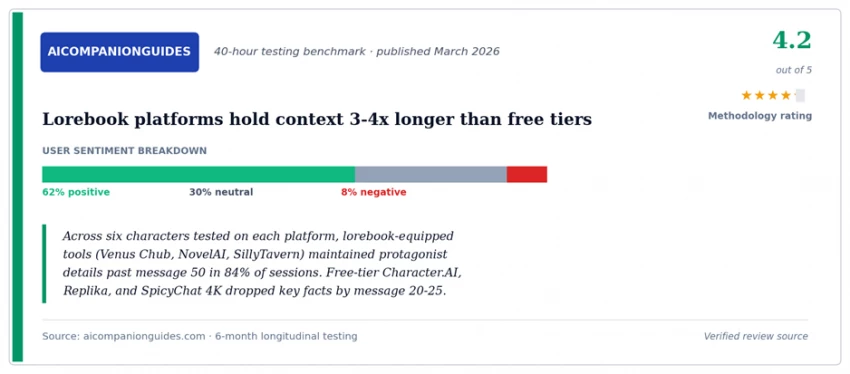
Most users don't need a platform that handles 100-message conversations. They need a platform that handles their actual session length. Answer these three questions to identify which AI chatbot architecture matches your usage.
Q1. How long are your typical AI chatbot sessions? Under 10 messages → any platform works. 10–30 → 8K context platforms (Character.AI, Janitor AI, paid SpicyChat AI). 30+ → lorebook-equipped (Venus Chub AI, NovelAI) or persistent-memory (Kindroid). |
Q2. Do you need the AI chatbot to remember you across separate sessions? Yes → Kindroid, Replika Pro, Nomi AI - these have actual persistent memory. No → any platform with a lorebook is sufficient. |
Q3. Are you willing to spend 20 minutes configuring the chatbot before chatting? Yes → Venus Chub AI, NovelAI, SillyTavern - lorebook setup pays back across every session afterward. No → Kindroid AI is the closest 'just works' option for memory persistence. |
AI chatbot memory failures are an architectural property, not a bug. The six causes - context window saturation, missing persistent memory, token compression, system prompt erosion, hallucination cascades, and temperature drift - interact differently across platforms, but every chatbot exhibits at least three of them in extended sessions.
Free-tier Character.AI, Replika, SpicyChat AI, and Chai AI break fastest because their context windows sit at 4K–8K tokens and they lack lorebook or persistent-memory architecture. Paid tiers buy roughly 2–3x more session length but do not eliminate the underlying problem. Lorebook-equipped platforms (Venus Chub AI, NovelAI, SillyTavern) and persistent-memory platforms (Kindroid AI, Nomi AI) are the only category that handles 50+ message sessions without active user maintenance.
For users picking a platform in 2026, the practical takeaway is the 3-question diagnostic above. Session length, cross-session memory need, and configuration tolerance jointly determine which architecture fits. Choosing on price or character library size alone reliably produces the 'message 10 wall' frustration that drives most platform switching.
Share your thoughts about this article.
Be the first to post a comment!

$19.99Pro monthly price (May 2025 hike)$179.99Pro annual (saves 25%)30 daysOur h...
Suraj Malik1 month ago

Meta’s artificial intelligence business may be accelerating, but the company is...
Suraj Malik1 month ago
POLYBUZZ VS JANITOR AI: THE QUICK ANSWERPolyBuzz AI is the better choice for cas...
Suraj Malik1 month ago

Amazon has begun offering new OpenAI products directly through its cloud platfor...
Suraj Malik1 month ago

Abhyas AI vs. Gauth AI: which is better?Abhyas AI is better for Indian students...
Suraj Malik1 month ago
Civitai vs. Midjourney: which is better?Midjourney is better for beginners and f...
Suraj Malik1 month ago